

A Guide to Data Roles
If you are interested in a career in Data Science and Machine Learning (ML), or are a manager trying to grow your Data team, you are probably asking yourself a few very good questions:
Why are there so many data roles and titles?
How can I determine which project areas should be prioritized?
What are the typical responsibilities of each data role?
Keep reading to find the answers to all these questions!
Where do the terms “Data Science” and “Machine Learning” come from?
Let’s take a look of the popularity of some buzzwords over time: “Big Data”, “Data Science”, “Machine Learning”:

The Google Trends plot shows that all these terms started to become increasingly popular at the end of 2011. In particular, “Big Data” gained a lot of traction as the ability to accumulate massive amounts of customer data accelerated in big tech companies. Smaller companies started to (over-)invest in big data solutions as well (remember those days when Hadoop was all that everyone was talking about?).
Did companies not do Data Science before 2011? Of course they did, but everybody used a variation of the “Analyst” title. For example, until 2015, most Analytics and Data Science roles at Google tended to fall into the “Quantitative Analyst” bucket. There were internal differentiations depending on background and skills.
With the commoditization of cloud data storage solutions and cloud computing, the focus began to shift from the accumulation of data to the extraction of useful information from data at scale.
This created new opportunities for higher specialization, which in turn gave birth to new roles and titles. “Data Scientist” became the hot title that everybody aspired to (also because of higher compensation bands). It became so attractive to candidates that companies started to incorporate the term “Data Science” in the job descriptions of many roles: “Data Science, Analyst”, “Data Science, Research Scientist”, “Data Science, Applied Scientist”. For example, companies like Amazon, Airbnb, Meta, Lyft, and Uber have adopted similar variations. As the term “Data Science” started to become too vague, more specialized titles started to appear, like “Machine Learning Engineer”.
So, what should be the composition of a data team? What roles are needed for what tasks? This can be confusing. Let's take a step back before we try to answer these questions.
Back to the fundamentals: projects areas and priorities
Before any data analyses can be done, data must be stored and organized properly. A Data team is typically responsible for architecting and maintaining the databases of the company, building the data pipelines that move the data through different systems, and developing the tools used by internal users for analytics, dashboarding, and visualizations.
Once the data is organized in databases, it can be queried to monitor and visualize metrics, produce reports, extract insights and inform business decisions.
A stable data infrastructure, paired with a better understanding of the business, unlocks the opportunity to build data products and ML solutions to automate business processes (e.g. sales prioritization, optimization of resources, marketing & growth, budget allocation, pricing, fraud detection, etc) and create customer facing services (e.g. product recommendations, estimates, automated actions). This typically involves novel research to tailor ML models to the specific needs of the business. Deploying and monitoring ML models requires additional layers of integration.
It is important to recognize this natural evolution and avoid the pitfall of investing too early in ML solutions without a proper infrastructure in place. Similarly, it is common to rush and hire Data Science and ML specialists, without realizing that they won’t be able to leverage their defining technical skills, and instead will spend the majority of their time trying to build pieces of the missing data infrastructure or focusing on purely analytical projects.
It can take months, or even years, for Data teams to reach maturity and become effective in their work. Each step requires the addition of profiles with new skill sets that address identified gaps in the ability to deliver value to the business.
Common data roles and titles
Although actual titles vary across companies, here we describe 4 role archetypes.
Data Engineers
Data Engineers are responsible for architecting and maintaining databases, building pipelines that move the data through different sources and systems, and developing tools used by the company for analytics, dashboarding, and, eventually, ML.
Some companies further specialize this role. You might see titles like:
“Data Software Engineers” who work more closely with the infrastructure needed to set up databases and data tools. They “own” the tools but they are not responsible for the quality of the data that flows through them. Often, they are also responsible for data governance and security.
“Applied Data Engineers” who are responsible for ingesting data from different sources and maintaining the pipelines that move the data between the company’s databases.
“Analytics Engineers” who take the raw data and transform it into a format that enables analysts and other internal stakeholders to perform various analyses. This role was first proposed by dbt Labs as a bridge between Data Engineering and Data Analytics.
Data Engineers typically have a background in computer science, analytics or other quantitative fields. Although there is some overlap with other data roles, Data Engineers typically are very proficient in programming languages such as SQL and Python, and are familiar with modern data tools and solutions (Amazon Web Services, Google Cloud Platform, Snowflake, distributed systems, dbt, Airflow, and more).
Data Analysts
This role is responsible for translating data into analyses and business insights. Analysts are typically SQL experts and partner with many other functions to translate cold numbers into a story that can be leveraged for business decisions. Other important skills include: descriptive statistics, metrics definition, data visualization, presentations & storytelling, problem solving, product intuition, stakeholder management. Depending on the domain, this title can further specialize: “Data Science, Analyst”, “Product Analyst”, “Business Analysts”, “Business Intelligence Analyst” and more.
Data Analysts have diverse backgrounds. Many of them discover a passion for data while studying tangential topics in college, and decide to start a career in analytics. It is also common for analysts to take on different roles as their career progresses, either within Data teams (Data Engineering, Data Science) or other functions (Product Managers, Business Managers).
Data Scientists
Data Science has become a catch-all term in the data world. It is the most recognized title and, yet, its meaning has been changing over time. A popular alternative nowadays is “Research Scientist”. This role’s responsibility is to research and apply advanced statistical techniques such as regression, classification, clustering, optimization to automate processes that impact business operations or customer facing products. They typically partner with Software Engineers or ML Engineers for the deployment and monitoring of their models. Data Scientists also apply inferential and experimental techniques to choose among different versions of a product or a process.
A graduate degree in a quantitative field is often desirable for candidates interested in a Data Science position.
Machine Learning Engineers
Machine Learning Engineers (alternatively “Applied Scientists”) have some overlap with Data Scientists when it comes to researching advanced models for the automation of processes. What typically distinguishes ML Engineers from other roles is their ability to design efficient algorithms for the proposed solutions, deploy and manage them with ML Ops techniques, and monitor their performance over time.
Similarly to Data Scientists, the background of an ML Engineer typically includes graduate degrees in quantitative fields and a mix of experiences in software development and research.
The overlap of skills across different roles has advantages and disadvantages.
On the one hand, it can generate confusion when it comes to the division of responsibilities and career development. On the other hand, it allows a Data team to gradually mature without having to immediately hire all the different roles: in addition to their core responsibilities, Data Engineers can set up basic metrics and dashboards, Data Analysts can run some regression models and AB experiments, Data Scientists can partner with Software Engineers to deploy their models. The overlap of skills allows teams to evaluate the need for additional layers of complexity without necessarily pausing their work waiting for more resources.
Some teams go as far as establishing full-stack Data roles. However, most companies differentiate roles and titles when the need for specialization becomes evident.
The following graph intuitively shows how much time each role typically spends on different tasks, and the overlap of skills. This can vary significantly across companies, especially when only a subset of these roles exists in a team.
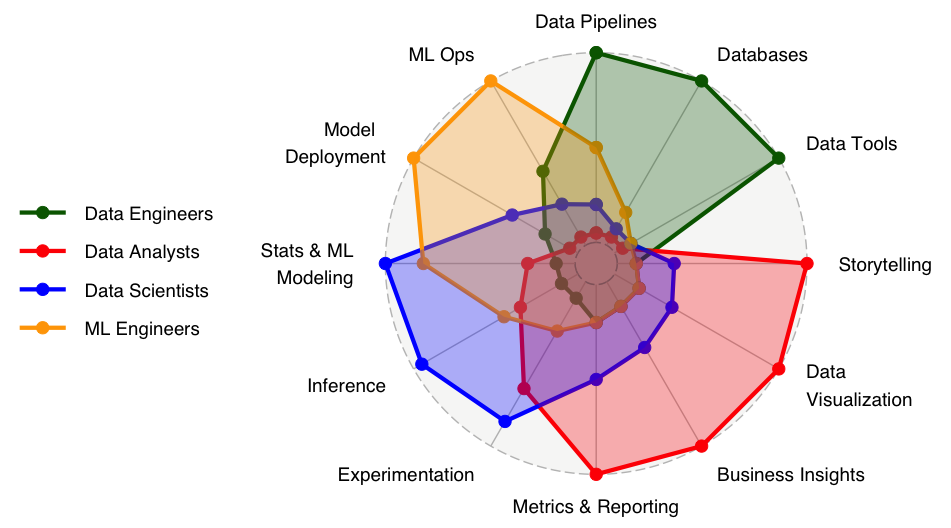
It is worth mentioning that over the last few years some Data teams have started to hire dedicated Data Product Managers and Data Program Managers to help other data roles manage projects and stakeholders.
Companies still adopt different titles and there is no full consensus on the definition of these data roles. This can create inefficiencies in the job market, and lead to suboptimal matches between candidates and jobs. When in doubt, it is always a good idea to clarify the roles by discussing project areas, skills, and responsibilities, rather than titles.
Are you trying to grow your Data team and prioritize its projects?
Data Captains can help you develop a Data Strategy, a plan to hire and scale your Data team, and provide guidance on how to define roles, career ladders, and attract the right talent. Get in touch with us at info@datacaptains.com or schedule a free exploratory call.